Why and how should you backup your Salesforce data?
By Vinny Choinski, Triptych Info
Effectively managing customer relationships is key to the success of any organization. To manage these relationships, businesses often look to cloud-based CRM (customer relationship management) applications like Salesforce. Now, these applications are considered business-critical and as such, organizations must consider implementing enterprise class data protection for these strategic assets.
The Challenge: Protecting SaaS Data
Being in the cloud does not mean by default you have the proper level of data protection, it may provide some levels of resiliency, but there are still lots of ways to compromise, corrupt, or lose data in your CRM or more specifically your Salesforce environment. A successful recovery depends on a solution that can create the most complete and up-to-date backup image of your data. The solution must also be able to deliver enterprise class performance because poor performance doesn’t just impact backup windows and recovery SLA’s, it can actually impact the quality of the backup data itself.

When it comes to restore, it’s important to remember that by design Salesforce cannot recover all elements of a Salesforce Org. It’s critical that any deployed solution can reduce or mitigate data transformations that occur as part of the natural recovery process and verify that the recovered environment integrates with existing IT operations.
Additionally, the ability to support flexible recovery options (e.g., single, partial, and full restores) will improve success rates and reduce recovery time.
You can read more about this in “The Complete Guide to Salesforce Backup and Restore” here.
Is your Salesforce Backup Missing Critical Data?
Salesforce performs real-time replication to disk at each data center, and near real-time data replication between the production data center and the disaster recovery center.
However, there are still many reasons enterprise class backup capabilities should be deployed to protect Salesforce information. This includes recovering from data corruption whether it’s unintended user error or malicious activity, preparing for a data migration or data archive, replicating data to a data warehouse for analytics, or to make a copy for development purposes. In addition, cyber-criminals that once overlooked these applications now specifically target them as they work to increase the blast area of their cyber-attacks.
So, what’s important to consider when creating a good Salesforce backup? Ideally, a backup should give a representation of the data at a certain point in time. However, with Salesforce, while the backup is being performed, data can be modified by users. The longer the backup process lasts, the more discrepancies you might get at the end of the process.
The graphic below details how discrepancies occur between the production environment and a backup copy. On the left side of the figure, we see the start of the backup process. Next, the account portion of the backup job is completed. However, between the completion of the account backup and the start of the contacts backup a user creates a new account and a new contact. Finally, the contacts portion completes and the backup ends. This created the two discrepancies detailed below.
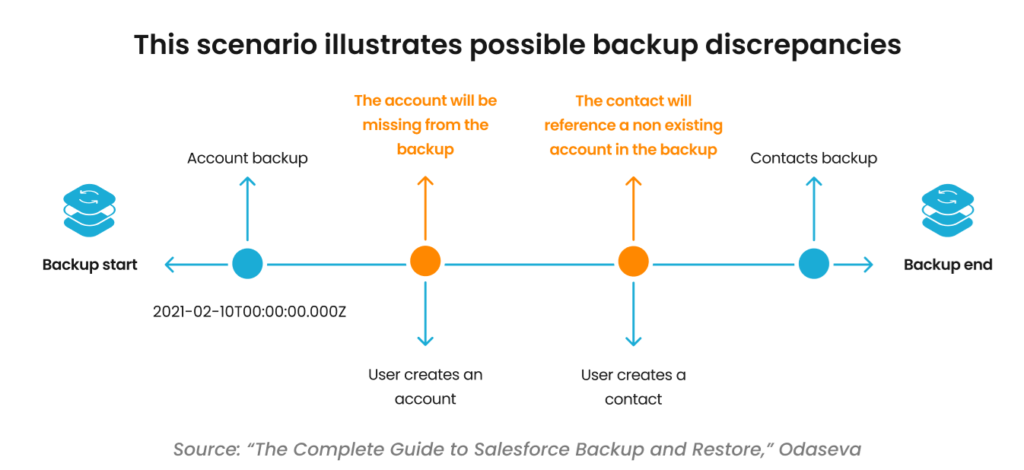
To address these discrepancies, a backup solution should have the ability to launch an incremental backup for accounts that were created/modified during the original backup job. The incremental would pick up the new account updates and minimize the time spent by the backup process because it would only need to capture a very small amount of changed data.
Is Poor Backup Performance Impacting your Salesforce Data Quality and Recovery SLAs?
Performance is a key element to any data protection solution. It is especially important in multi-tenant Salesforce environments because unlike many other applications, such as a traditional database, it can’t be paused or quiesced to create a clean synchronized backup. That is why Salesforce created different data management APIs to handle the different types of data that reside within each environment and why being able to leverage all these different APIs is so critical to successful data protection.
In addition, delivering the right performance in Salesforce is often a delicate balance between running as many backup processes as possible in parallel for the best performance and managing Governor Limits. These limits are intentionally set boundaries for the shared environments designed to keep a runaway process from impacting a whole ecosystem.
Each API has different data management capabilities that when properly aligned to specific Salesforce data enable better management of Salesforce limits or the ability to get more work done with fewer API calls. The APIs include a BULK API which is often leveraged to increase performance for larger data sets because of its parallelization capabilities. Depending on the type of data, the REST API (representational state transfer) and SOAP (simple object access protocol) can also be leveraged because not all data types are as quickly supported by BULK API. Additionally, REST or SOAP are not subject to BULK-specific governor limits.
The graphic below shows backup metrics provided by Odaseva based on a subset of Salesforce data with 200 billion records. The data shows the REST API reached 10 million records per hour while the BULK API reached 350 million records per hour. Typically, when dealing with larger data sets, the BULK API delivers superior performance and scalability over the REST API.
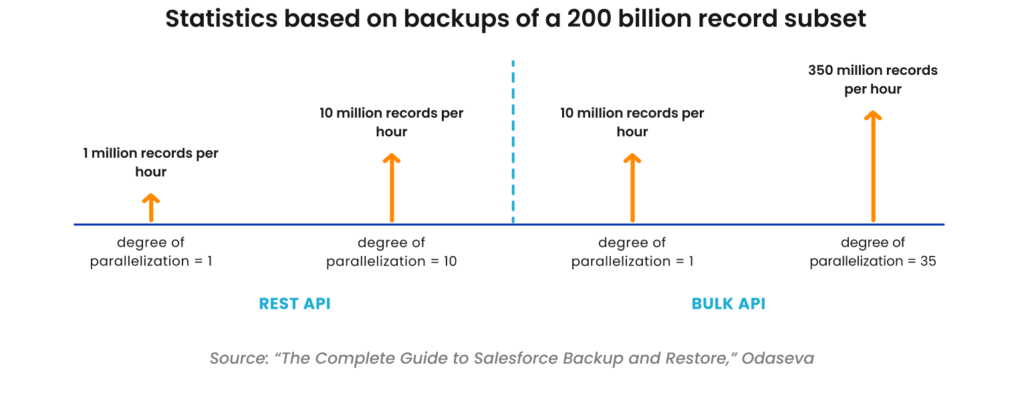
It should be noted that the degree of parallelization has been set to 10 for the REST API based on Odaseva’s field project experience. Going above 10 usually does not accelerate the process for the REST API. For the BULK API the degree of parallelization was set to 35. This setting was also based on Odaseva field experience.
Can you Support Different Restore Types for Different Salesforce Data Loss Issues?
Not all data loss issues are the same, and when it comes to recovering data for a business-critical application, time is of the essence. You need to reduce downtime as much as possible. That is why the following elements must be considered in the process. What is the scope of the recovery? Does the restore need to align with your Salesforce DRP (disaster recovery plan) or are you just restoring a specific version of the data, metadata, or document?
A recovery plan not only needs to include the tasks and steps for restore but also the steps needed to minimize the impact on the business and the impact to Salesforce itself. This includes minimizing any data transformation (discussed in the next section) that happens during restore. The ability to handle different types of restore processes is critical to improving performance, minimizing the number of manual tasks and minimizing the impact on the current and future state of the Salesforce application schema. Also, the importance of automation can’t be overlooked. In a large-scale enterprise, automation is almost a necessity. It can help solve common and repetitive restore roadblocks, provide error logs for manual intervention when needed, and restore the data relationships that are so key to the Salesforce environment.
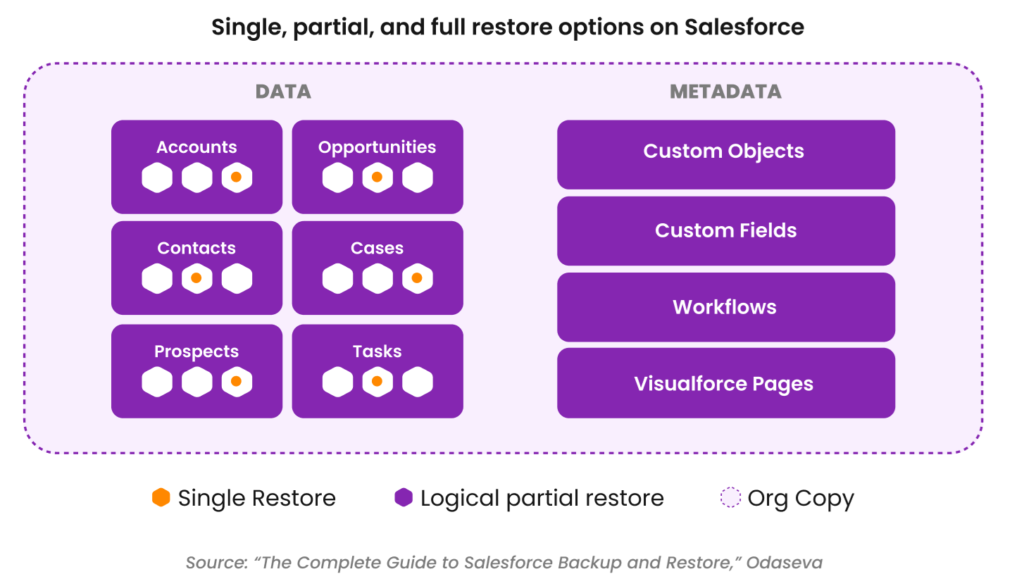
The graphic above shows the different types of restores that are key to a successful Salesforce recovery. It also shows some of the objects that can be recovered. A good data protection solution will “understand” the interdependencies between these objects and allow a user to recover only the data that needs to be recovered for the quickest possible path to returning to normal business operations.
Will a Salesforce Recovery Integrate with Your Existing IT Operation Processes?
By design, Salesforce may transform your data during the restore process. These transformations can range from a record ID to audit fields and can also include customizations such as workflow fields thus compounding the overall scope of transformations. In fact, depending on the environment and the recovery type as much as 85% of data could have some form of transformation after a restore.
A key element to restoring Salesforce as closely as possible to its original state after a data integrity issue is the ability to adapt the restore process such that transformations will be minimized or mitigated. The graphic below shows a simple recovery process versus a more advanced recovery process.
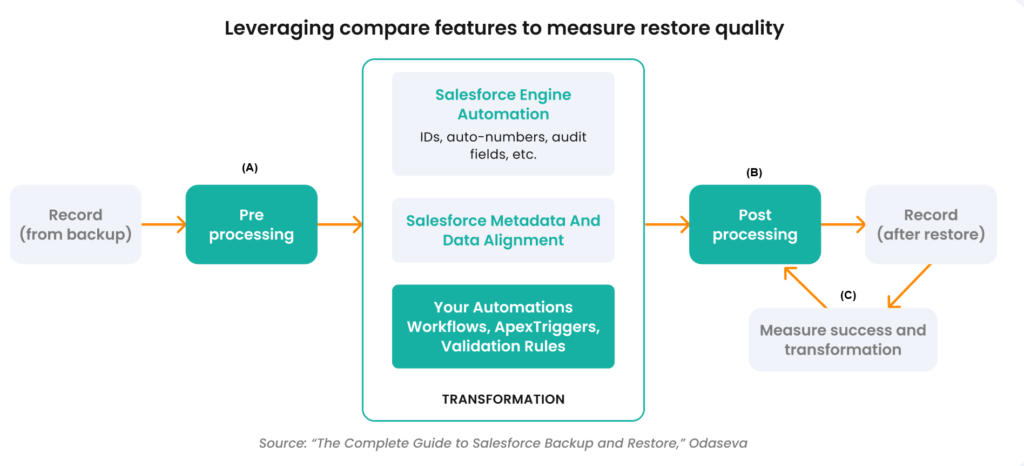
The first image above shows a simple restore of the data without any additional processing. The second image above shows the introduction of additional processing to the recovery process. This includes (A) pre-processing steps to minimize transformations that will occur during the restore process by tweaking the Salesforce system. It also includes (B) post-processing steps to adjust transformations that have occurred during the restore process to get closer to the original data. Applying pre- and post-processing steps can minimize transformation by as much as 80% over the simple restore process. Finally, a validation step (C) was added to measure the success of the data transformation mitigation efforts.
Conclusion
We backup data so that if we need to restore, we can resume normal business operations as quickly as possible. This includes restoring access to business-critical applications such as Salesforce. To achieve this, we need complete backups because recovering the data does not always mean you have recovered the whole environment.
Imagine completing a complex restore only to find out the recovery has broken reporting and analytics, or worse, critical logistics management information is missing from your environment. How can you make decisions based on transaction history and activity if that information is gone?
When it comes to protecting business-critical applications, you need an enterprise-strength data protection solution.
To learn more about properly protecting Salesforce data, read “The Complete Guide to Salesforce Backup and Restore” here.
View other stories

Recovery-Ready or Just Backed Up? Mastering Salesforce Data Recovery Planning

Salesforce RTO and RPO: Everything You Need to Know About Data Recovery Planning

How Odaseva Uses AI to Predict Governor Limits and Other Analytics

